第一章:Reinforcement Learning Basic Concepts
1. 基础元素:以 Grid World 为例
我们使用一个 的格子世界作为贯穿本章的示例。
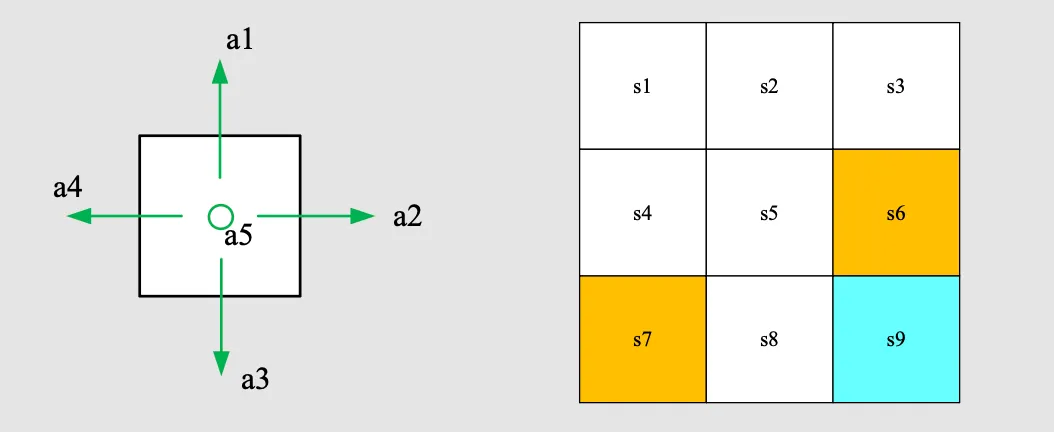
1.1 State
- 定义:Agent 相对于 Environment 的位置或状态。
- State Space :所有可能 State 的集合。
- 。
1.2 Action
- Action Space :某个 State 下 Agent 可以采取的所有 Action 的集合。
- 。
1.3 State Transition
- 定义:Agent 采取 Action 后,从当前 State 移动到下一个 State 的过程。
- 。
- 边界与障碍:
- Boundary:撞墙后反弹回原位(如 )。
- Forbidden Area:
- Accessible:可进入但受罚(本课程设定)。
- Inaccessible:有墙阻隔,保持原地。
- 表示方法:
- Tabular Representation:仅适用于 Deterministic 环境。
- State Transition Probability:适用于 Stochastic 环境。
1.4 Policy
- 定义:指导 Agent 在某个 State 下采取什么 Action。
- 数学表示:条件概率分布 。
- 分类:
- Deterministic Policy: (特定动作)。
- Stochastic Policy: (概率分布)。
1.5 Reward
- 定义:执行 Action 后 Environment 反馈的实数值。
- 作用:
- Encouragement:Positive Reward。
- Punishment:Negative Reward。
- 数学表示:。
- 设定:
2. 交互过程与评估
2.1 Trajectory
- 定义:State-Action-Reward chain。
2.2 Return
- Reward ():单步即时反馈。
- Return ():Trajectory 上所有 Reward 的总和。
- Discounted Return:引入 Discount Rate 。
- :Short-sighted(重视近期)。
- :Far-sighted(重视远期)。
2.3 Episode
- Episode:有限步的任务,通常在达到 Terminal State 后停止。
- 任务处理:
- Absorbing State:进入后不再离开,Reward 为 0。
- Normal State:可继续行动,反复获得 Reward(本课程采用,将 Episodic 任务转化为 Continuing 任务)。
3. Markov Decision Process (MDP)
MDP 是 RL 的数学框架,包含以下核心要素:
3.1 Sets
- State Space
- Action Space
- Reward Set
3.2 Dynamics / Model
- State Transition Probability:
- Reward Probability:
3.3 Policy
- :在 State 选择 Action 的概率。
3.4 Markov Property
- Memoryless Property:未来状态仅取决于当前 State 和 Action。
4. MDP vs MP
- MDP (Markov Decision Process):包含 Action 选择。
- MP (Markov Process):不含 Action,状态按固定概率转移。
- 关系:MDP 固定 Policy 后退化为 MP。
